![[Review] NeRF : Neural Radiance Fields](https://cubec.link/wp-content/uploads/2022/08/capture_200308934_7.png)
Problem
View synthesis는 여러 view에서 촬영한 이미지가 주어졌을 때 새로운 view에서의 이미지를 추론해내는 문제입니다. 저자는 scene을 neural radiance field라는 새로운 표현 방식을 통해 이 문제를 해결합니다.
What is NeRF?
Neural radiance field는 scene을 표현하는 MLP network입니다. 이 신경망에는 3차원 점의 좌표(x, y, z)와 view 방향(θ, ϕ)이 입력으로 주어지고, 색상 값(R, G, B)과 volume 밀도 값(σ)을 출력으로 내놓습니다.
F_\Theta : (x, y, z, \theta, \phi) \rightarrow (R, G, B, \sigma)
σ을 사용하는 것은 occlusion을 구현하기 위함입니다. Optical depth를 나타내는 파라미터라고 생각하면 적절할 것 같습니다. 일관성을 위해 σ는 view 방향에 independent하도록 신경망을 설계하였습니다.
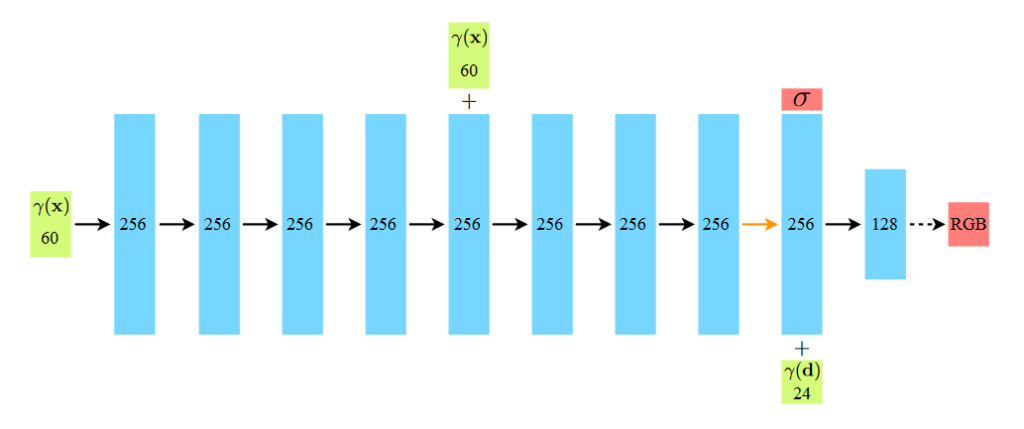
MLP는 두 단계로 구성됩니다. 각 layer에는 모두 ReLU activation이 사용됩니다.
(1) 좌표 (x, y, z)를 입력으로 받아, σ 및 256차원의 feature vector를 출력하는 단계. 256개의 channel을 가진 fully-connected layer 8개로 구성된 MLP를 이용합니다.
(2) 첫 단계에서 구한 feature vector과 view 방향(θ, ϕ)을 입력으로 받아 RGB 색상값을 출력하는 단계, 128개의 채널을 가진 하나의 fully-connected layer를 이용합니다.
How to Render
NeRF가 가진 정보는 3차원입니다. 이를 카메라에 투영해서 2차원 이미지를 만들 수 있어야 합니다. 이 때 고전적인 volume rendering 방식을 활용합니다. 카메라 광선을 r(t)=o+td라고 하면, 색상 C(r)은 이론상 다음과 같습니다.
C(\bold r) = \int^{t_f}_{t_n} T(t)\sigma(\bold r(t))\bold c(\bold r(t), \bold d) dt, \text{ where } T(t)=\exp(-\int^t_{t_n}\sigma(\bold r(s))ds)
T(t)는 tn으로부터 특정 지점(t)까지의 투과율을 의미합니다. 간단한 형태의 volume rendering 식임을 알 수 있습니다. 실제로는 수치해석적으로 추정해야 하므로, tn에서 tf까지의 구간을 N개의 균등한 구간으로 나누어 각 구간마다 샘플을 랜덤으로 하나씩 추출하는 stratified sampling 방식을 사용합니다. 그렇게 추출한 샘플의 i번째 위치를 ti라고 하면, 색상은 다음과 같은 식으로 계산할 수 있을 것입니다.
\hat C(\bold r) = \sum^{N}_{i=1} T_i(1-\exp(-\sigma_i\delta_i))\bold c_i, \text{ where } T_i=\exp(-\sum^{i-1}_{j=1}\sigma_j \delta_j)
여기서 δi=ti+1-ti는 인접한 샘플 간의 간격입니다. 이러한 형태로 나타내면 MLP의 출력 (R, G, B, σ)에 따라 미분 가능한 형태가 되며, 따라서 경사강하법을 기반으로 한 최적화 알고리즘을 적용할 수 있게 됩니다.
Optimization
지금까지의 설명이 NeRF의 핵심이었습니다. 하지만 이 방식으로는 SOTA 수준의 퀄리티를 얻을 수 없다고 합니다. 그래서 저자는 두 가지 방식의 최적화 방안 – positional encoding, hierarchical volume sampling – 을 제안합니다.
Positional Encoding

해당 MLP를 그대로 사용할 경우 문제 중 하나는, high-frequency에 해당하는 색상과 형태를 잘 잡아내지 못한다는 것입니다. 이 문제를 해결하기 위해 각 입력값을 고차원의 값으로 매핑하는 방식을 사용합니다.
\gamma : \R \rightarrow \R^{2L} \newline
\gamma(p) = (\sin(2^0\pi p), \cos(2^0\pi p), \cdots,\sin(2^{L-1}\pi p), \cos(2^{L-1}\pi p) )
위치 좌표(x, y, z)에 대해서는 L=10, view 방향(θ, ϕ)에 대해서는 L=4로 설정했다고 합니다. 이를 통해 높은 주파수 대역의 정보에 대한 성능을 향상시켰습니다.
Hierarchical Volume Sampling
사실 stratified sampling 방식으로 균일한 샘플링을 하는 것은 렌더링 측면에서 비효율적입니다. 렌더링에 영향을 미치지 않는 지역, 가령 빈 공간이나 엄폐된 공간까지 반복적으로 샘플링되기 때문입니다. 샘플링 방식을 하나 더 추가하여 두 개의 네트워크를 최적화합니다. 핵심은 최종 색상에 많이 기여하는 위치에 대한 샘플링을 더 많이 하는 것입니다. Importance sampling을 통해 variance를 줄이는 과정과 유사합니다.
첫 번째는 coarse 네트워크로, Nc개의 위치를 stratified sampling으로 정한 후, 앞에서 설명한 C(r)을 구하는 식을 이용하여 색상을 평가합니다. 두 번째는 fine 네트워크입니다. 이 방식은 coarse 네트워크에서 샘플링한 값을 이용합니다. Coarse 네트워크에서 광선을 따라 존재하는 각 샘플링 색상의 가중치는 다음과 같이 계산할 수 있습니다.
\hat C_c(\bold r) = \sum^{N_c}_{i=1} w_i c_i, \text{ where } w_i=T_i(1-\exp(-\sigma_i\delta_i))
이 가중치를 normalize한 후 piecewise-constant PDF에 맞추어 Nf개를 샘플링합니다. 마지막으로 Nc + Nf개의 샘플에 대해 적분하여 렌더링된 색상을 계산하게 됩니다. 이것이 fine 네트워크입니다.
Implementation Detail
각각의 scene에 대해서 신경망을 학습시킵니다. 각 scene에 필요한 데이터셋은 다음과 같습니다.
- RGB 이미지 여러 장
- 각 이미지에 대한 카메라 위치 및 내부 파라미터
- Scene 경계 정보, 실제 데이터셋에 대해서는 scene을 normalized device coordinate로 변환하여 cube 형태가 되게 합니다.
각 iteration마다 카메라 광선들을 데이터셋으로부터 랜덤하게 추출합니다. 목적함수는 다음과 같습니다.
L = \sum_{r\in R}[\text{\textbardbl}\hat{C_c}(\bold r) - C(\bold r)\text{\textbardbl}^2+[\text{\textbardbl}\hat{C_f}(\bold r) - C(\bold r)\text{\textbardbl}^2]
R은 추출된 광선 집합을 의미합니다. 각 batch 별 실제 색상과 각 network 간의 제곱 오차의 합을 최소화해야 한다는 것을 알 수 있습니다.
실험에서는 4096개의 광선을 하나의 batch로 두고, Nc=64, Nf=128로 두었습니다. Adam optimizer을 이용하고 learning rate는 5×10-4에서 지수적으로 감소시켜 최종적으로 5×10-5까지 줄어들도록 했습니다. 각 scene에 대한 MLP가 수렴하기까지 NVIDIA V100 GPU에서 10만-30만 회의 iteration, 시간으로는 1-2일이 걸렸다고 합니다.
Results
3가지 데이터셋에 대해서 실험했습니다.
- Diffuse Synthetic 360° – Lambertian 표면을 가진 DeepVoxels 데이터셋
- Realistic Synthetic 360° – 저자가 직접 만든 non-lambertian 표면 데이터셋
- Real Forward-Facing – 실제로 촬영된, 주로 한 방향을 바라보는 사진들의 데이터셋
Quantitative Analysis

PSNR/SSIM (낮을수록 좋음), LPIPS (높을수록 좋음)
거의 모든 데이터셋과 metric 쌍에 대해 가장 좋은 성능을 보이는 것을 알 수 있습니다.
Qualitative Analysis

Pros / Cons
NeRF의 장점은 기존의 방식들(NV/SRN/LLFF)보다 퀄리티가 높고, 신경망의 크기가 작다는 것입니다. 신경망 파라미터의 용량은 불과 약 5MB 정도에 불과합니다. 이는 입력 이미지 하나의 용량보다도 작습니다.
반면 가장 큰 단점은 훈련 시간에 있습니다. 하나의 scene을 트레이닝하는데 최소 12시간이 걸린다고 합니다.
Ablation Studies
애블레이션 연구는 제안한 요소를 검증하는 방식 중 하나입니다. 요소를 제거한 후 비교해 봄으로써 연구에서 제안한 아이디어가 얼마나 효과적인지를 판단합니다. 여기서는 positional encoding, view-dependence, hierarchical sampling을 제거하면서 신경망의 성능을 비교합니다. 또한 입력 데이터셋 크기 및 PE의 최대 주파수을 변경하면서 비교합니다.

요소 중 하나라도 제거될 경우 최종 모델보다 낮은 성능을 보여주는 것을 알 수 있습니다. 또한 25개의 이미지만을 사용해도 100개의 이미지를 사용하는 기존의 방식들보다 성능이 우월하다고 합니다. Frequency의 경우 10개를 넘어가면 더 이상 성능이 향상되지 않는 것을 볼 수 있는데, 이는 아마도 입력 이미지의 최대 주파수(약 210=1024)를 넘게 되면 positional encoding의 의미가 없기 때문으로 보입니다.
Conclusion
MLP를 이용하여 scene을 5D NeRF 형태로 표현할 수 있었고, 이전의 연구들보다 훨씬 좋은 성능을 보였습니다. 복잡한 scene을 그래픽스로 표현하기 위한 새로운 방안을 제시했다고 할 수 있겠습니다. 다만 NeRF를 학습시키거나 렌더링할 때 최적화할 요소가 아직 더 남아 있을 것으로 보입니다.