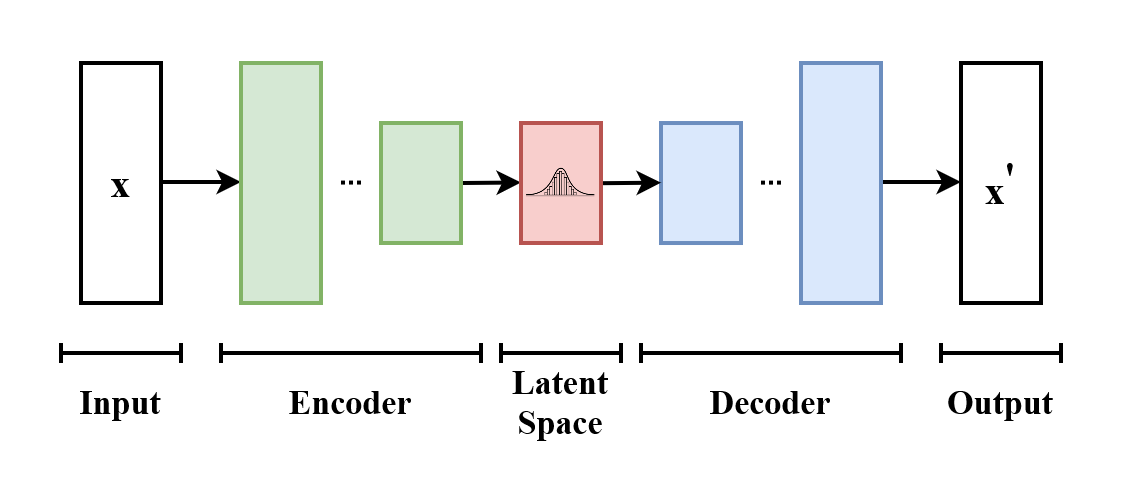
생성형 AI에서 자주 사용되는 Variational Autoencoder(VAE)의 개념을 기초부터 정리합니다.
Dimensionality Reduction
이미지와 같은 고차원의 데이터는 그대로 다루기 어렵습니다. 데이터의 특성을 나타낼 수 있는 중요한 feature들을 선별해서 가져올 수 있어야 합니다. 이를 위해 차원 축소(dimensionality reduction)를 진행합니다.
차원 축소를 위한 두 가지 구조, encoder와 decoder가 쌍으로 존재합니다.
- Encoder: Input space를 저차원의 latent space(=encoded space)로 매핑합니다.
- Decoder: Latent space를 다시 고차원의 input space로 매핑합니다.

Encoder와 decoder를 거치면서 데이터의 loss가 발생할 수 있습니다. 차원 축소가 잘 이루어지려면 encoder/decoder 쌍에 의한 정보 손실이 최대한 적도록 모델을 학습시켜야 합니다. 이 정보 손실을 reconstruction error로 정의합니다.
(e^*, d^*) = \argmin_{(e, d)\in E \times D} \epsilon(x, d(e(x))Autoencoder
Encoder와 decoder로 neural network를 사용하는 형태의 차원 축소 모델입니다.
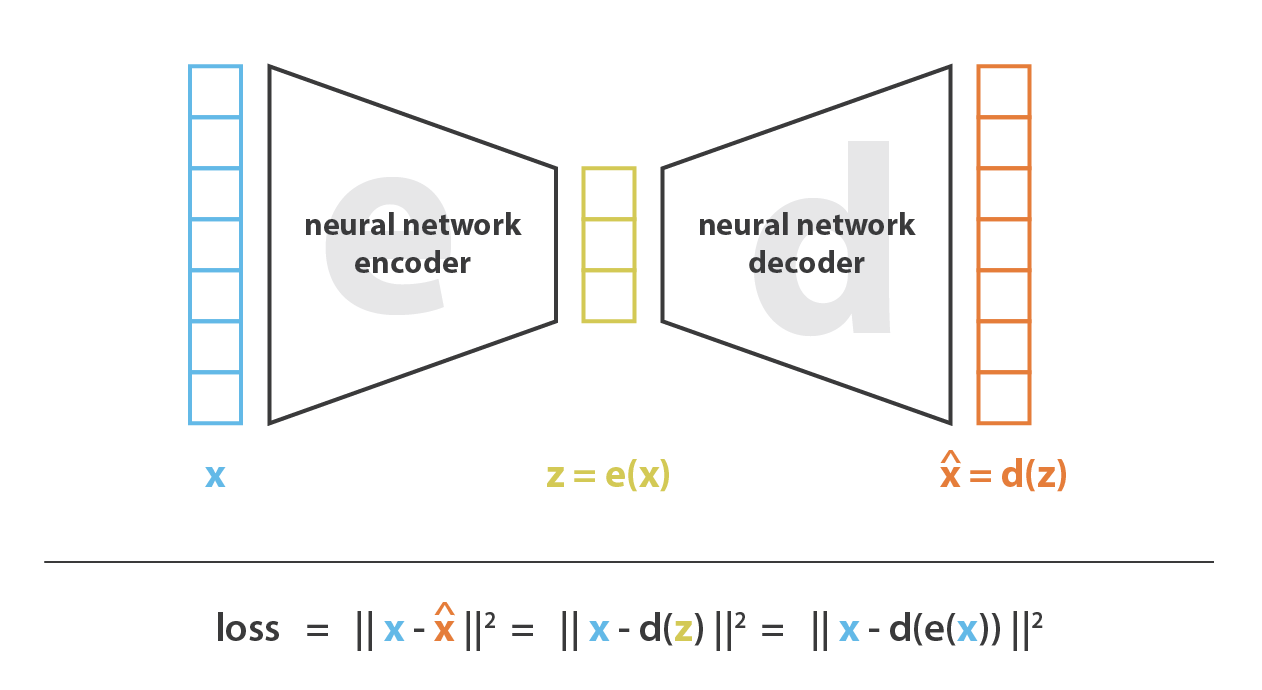
Autoencoder의 reconstruction error를 최소화하는 방식으로 모델을 학습합니다. 이러면 직관적으로 bottleneck에 해당하는 latent space에는 데이터의 핵심 구조에 대한 정보만을 담도록 학습할 것이라 기대할 수 있을 것입니다.
Limitations of Autoencoder
이미지와 같은 콘텐츠 생성에 위의 autoencoder를 사용할 수 있을까요? 언뜻 보면 충분히 가능할 것처럼 보입니다. Latent space에서 랜덤한 vector를 샘플링하고, 이를 decoder에 통과시키면 새 콘텐츠가 나올 것으로 보입니다. 하지만 실제로는 잘 되지 않는다고 하는데, 그 이유는 latent space가 잘 정규화되어 있지 않기 때문이라고 합니다 (lack of regularity).
Latent space가 정규화되기 위해서는 구체적으로 두 가지 조건을 만족해야 합니다.
- Continuity – latent space에서 가까운 데이터는 실제로도 비슷한 구조를 가진 데이터여야 합니다.
- Completeness – latent space에서 샘플링된 point는 decode를 통해 의미 있는 데이터로 변환되어야 합니다.
차원 축소의 목적은 단순히 차원을 줄이는 것이 아니라 latent space에서 중요한 데이터 구조를 보존하는 것에 있으며, reconstruction error만으로는 이를 보장할 수 없다는 것이 autoencoder의 한계입니다. 학습 시 모델이 특정 latent space에만 overfitting되도록 학습할 수 있고, 이 경우 error는 줄어들지만 latent space에서의 해석 가능성과 규칙성 또한 줄어들 수 있기 때문입니다.

극단적인 케이스로는, 이론상 모든 학습 데이터를 1차원의 latent space로 매핑시키면서 loss를 최소화할 수 있을 것입니다. 하지만 이러한 차원 축소 방식이 데이터를 표현하는 가장 좋은 방식이라고 할 수는 없을 것입니다. 근본적으로는 학습 과정에서 regularization이 자연스럽게 진행되도록 해야 합니다.
Variational Autoencoder
Variational autoencoder는 latent space의 overfitting을 방지할 수 있도록 학습하여 latent space가 잘 정규화되도록 합니다. 이를 통해 생성 프로세스에도 활용될 수 있도록 합니다.
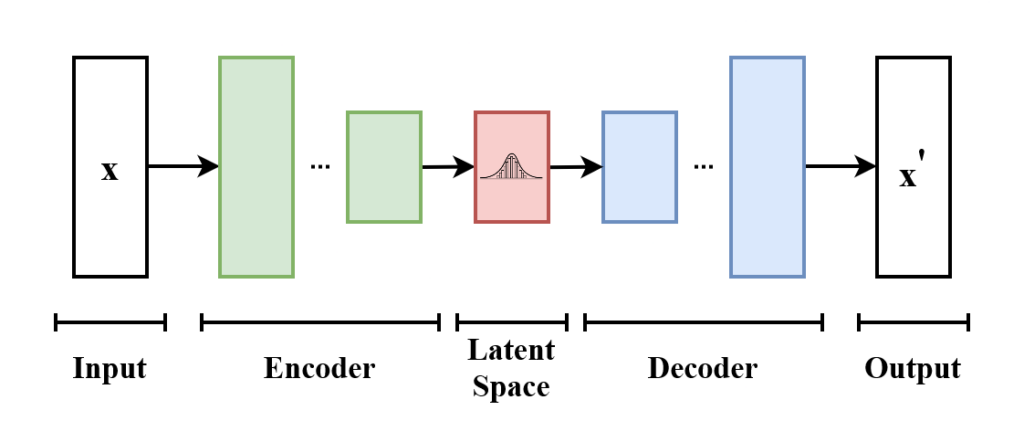
Latent space의 정규화를 위해 데이터 인코딩 시 deterministic한 vector로 인코딩하는 대신, 확률 분포로 encoding합니다. 전반적인 학습 과정은 다음과 같습니다.
- Input vector
x는 encoder에 의해 latent distributionp(z|x)로 인코딩됩니다. - Latent distribution에 기반해 확률적으로 latent vector
z를 샘플링합니다. - Decoder로 데이터를 reconstruct한 후 error를 계산합니다.
- Backpropagation을 통해 에러가 전파되어 encoder와 decoder weight를 학습합니다.
실제로는 latent distribution은 정규분포를 따르도록 합니다. Encoder에서 normal의 mean과 covariance matrix를 계산하는 방식으로 distribution을 표현합니다.
기존의 reconstruction error만으로는 latent space의 정규화가 보장되지 않으므로, latent layer에서 새로운 regularization error를 추가로 도입하였습니다. 이 error는 Encoder에 의한 확률분포를 N(0, I)의 표준정규분포와 가까워지도록 KL divergence를 최소화하는 방식으로 적용됩니다.
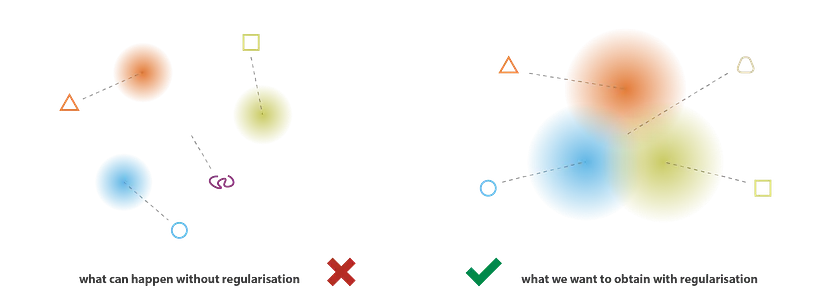
Regularization error를 도입하면
- 분포의 variance가 너무 작아지지 않고,
- 분포가 표준정규분포 형태에 가까워지며,
- 각 분포의 중심점이 origin(0)에 가까워지도록 학습됩니다.
그러므로 latent space 내에서 distribution이 서로 overlap되어 연속적인 gradient를 가질 수 있습니다. 이를 통해 정규화를 위한 두 가지 조건 – Completeness, Continuity – 을 만족할 수 있습니다.
Part 2에서 계속…

